

‧
4 min read
The story behind our AI Dataset Generator
Matthew Hefferon
‧ 4 min read
Share this article
At Metabase, I often need fake data to demo new features. I found myself digging through Kaggle, but not feeling very inspired, and wasting a lot of time searching. So I built a little tool to help me generate datasets and decided to open source it.
It ended up hitting the front page of Hacker News, got 600+ stars on GitHub, received contributions from a YC-backed startup, and was picked up by TLDR newsletter.
Why not Kaggle or ChatGPT
As mentioned above, I was feeling very uninspired by Kaggle datasets and kept turning to ChatGPT to generate fake data. I’d ask for something, get results back, visualize it, and spot issues. Bar charts all the same height, growth trends going the wrong way, not enough variation, etc. I found myself repeating that cycle and thought… maybe there’s a better way.
What I actually did
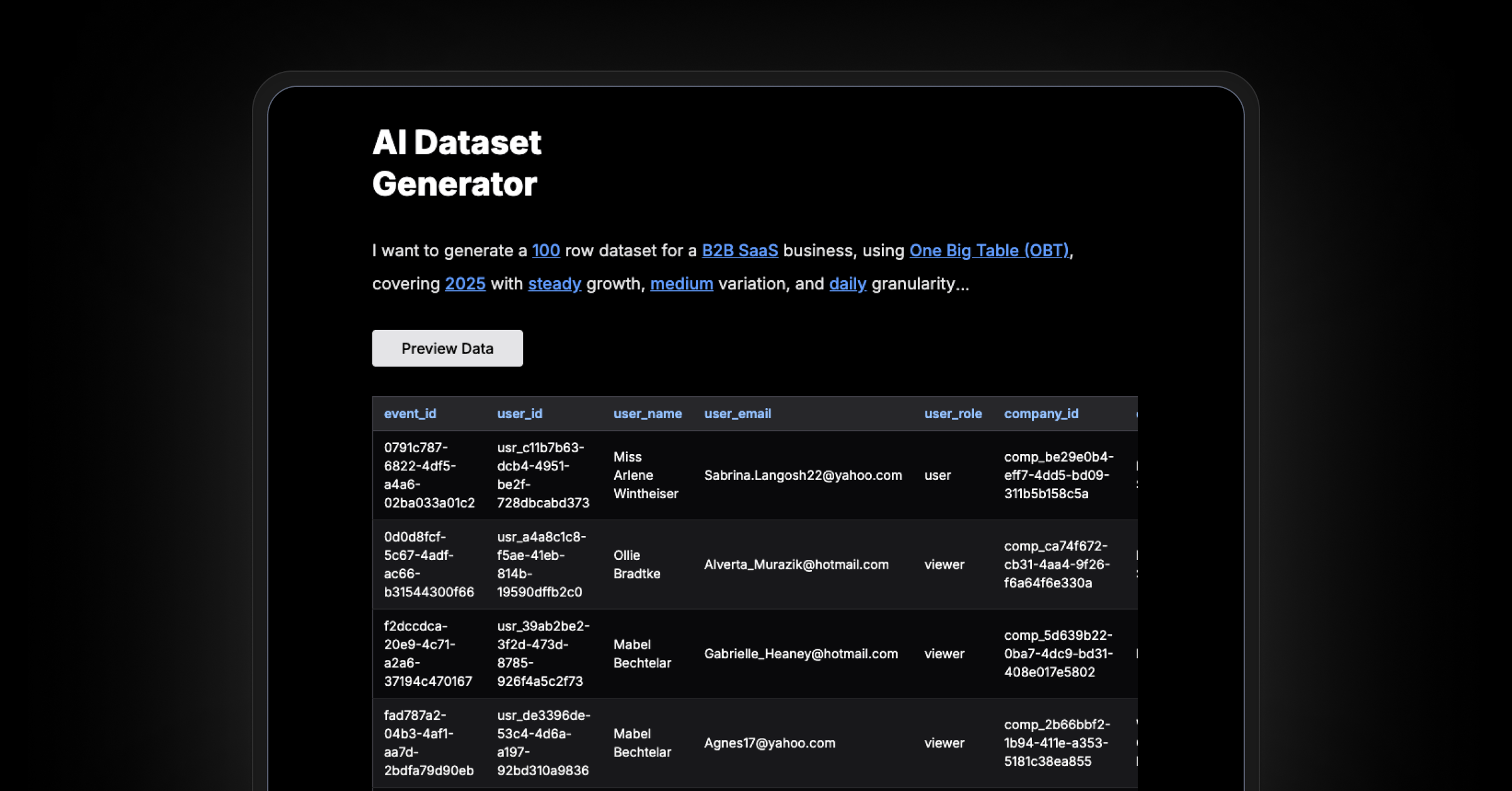
Since I’d already been writing prompts and had some experience, I figured, why not turn that process into a simple tool? So I converted my prompt inputs into a few dropdowns:
- Business type
- Row count
- Single or multi-table schema
- Date range
- Growth pattern
- Variation and granularity
You hit “Preview Data” and get back a sample schema and 10 rows of data. If it looks good, you can export a full dataset as CSV, SQL, or launch Metabase to explore it.
How It Works
Step 1: How schema generation works
When you hit “Preview Data,” the app sends a prompt to your selected LLM provider (OpenAI, Anthropic, or Google) via LiteLLM. It’s tailored to the business type and returns a JSON spec defining the tables, fields, relationships, and logic. Think of it as a blueprint for a believable dataset.
Originally, I was just generating the schema with ChatGPT. But after a few folks on Hacker News mentioned it’d be cool to switch models, we got an awesome PR that added LiteLLM support, so now you can swap between providers easily. Thanks for the contribution @manueltarouca!
Step 2: Rows are generated locally by the DataFactory
I originally had the LLM generate all the rows, but it was painfully slow, even for 100 rows. I tried splitting the job into batches, but that introduced new issues. For example, a user ID might be 001, 002, 003 in the first batch and something like u099, u100 in the second.
So I took a step back and had a deep discussion with Cursor. I needed something fast, more realistic, and cheaper to run. After some back and forth, I decided to build the DataFactory. It generates data locally using Faker.js and applies the schema + simulation rules from the LLM. It also enforces logic like:
- Realistic SaaS churn and pricing plans
- E-commerce subtotals, tax, and shipping that actually add up
- Healthcare claims where payouts never exceed procedure costs
Step 3: Performance and cost
By splitting it into two phases, the tool stays fast and surprisingly cheap. Schema generation is the only part that hits the LLM, and I wanted to make sure it wouldn’t lead me to bankruptcy. So I added token tracking and ran the numbers using a super advanced formula:
total_tokens × cost_per_token = ???
Turns out… not that bad. Most previews come in around $0.03–$0.05 with GPT-4o. After that, it’s all free. No extra API calls, just pure, 100%, Grade A data.
Try it yourself + contribute
It’s still early, so it’s not bulletproof. But if you need quick, realistic datasets, give it a try. Everything runs locally with Docker, and all you need is an API key from your favorite LLM provider to get started.
If you want to contribute, there’s plenty of room to jump in:
- Add new business types or tweak existing ones
- Improve schema logic or simulation rules
- Add your awesome feature here
The groundwork is already there. If you’ve got ideas, I’d love your help taking it further. Star it, fork it, or open a PR on GitHub.

