


The problem
Every month, Hacker News hosts a wildly popular thread: “Ask HN: Who is hiring?” It’s a treasure trove of job opportunities, but scrolling through endless walls of text to find your dream role feels like searching for a needle in a haystack.
The solution
I vibe coded a little project with Cursor that turns those Hacker News job posts into clean, searchable data using OpenAI for parsing, PostgreSQL for storage, and Metabase for visualizations. The Holy Trinity of data wrangling :)
What it does
- Fetches “Ask HN: Who is hiring?” threads via the Hacker News API
- Uses GPT to extract fields like company, role, location, salary, and contact
- Stores it all in a PostgreSQL database
- Spins up Metabase so you can search, filter, and explore
How it works
Fetch the thread
The script pulls a specific Hacker News thread using its ID (you can grab this from the URL of any “Ask HN: Who is hiring?” post).
Parse comments with GPT
I started with regex, but the unstructured formatting in each comment made it impossible to get clean, reliable data. So I switched to GPT. Each comment is passed into OpenAI using a structured prompt that extracts the relevant fields in JSON. Here’s the core of the prompt:
OPENAI_PROMPT = (
"You are a structured data parser for Hacker News job posts. "
"Extract the following fields as plain strings (no quotes, arrays, or brackets unless necessary):\n"
"- company: the name of the hiring company\n"
"- role: the job title or position name\n"
"- location: city/state/country or 'Remote' if applicable\n"
"- salary: salary range or note (e.g. '$120k--$150k', 'Competitive', etc.)\n"
"- contact: email address or direct application link (cleaned, no obfuscation like [at] or [dot])\n"
"- description: a cleaned-up version of the full job post, useful for search\n\n"
"Requirements:\n"
"- Output a flat JSON object using the keys above\n"
"- If any field is missing or not available, use null\n"
"- Do not include markdown, HTML, or formatting characters\n"
"- Fix obfuscated emails like 'name [at] domain [dot] com'\n"
"- Output only the JSON object, with no extra commentary.\n"
"- No trailing commas.\n\n"
"Job post:\n"
'\"\"\"{job_text}\"\"\"'
)
Store in PostgreSQL
Parsed results are saved in a jobs table:
CREATE SCHEMA IF NOT EXISTS hn;
CREATE TABLE hn.jobs (
hn_comment_id bigint primary key,
company text,
role text,
location text,
salary text,
contact text,
description text,
posted_at timestamp with time zone,
created_at timestamp with time zone default now(),
updated_at timestamp with time zone default now()
);
Explore in Metabase
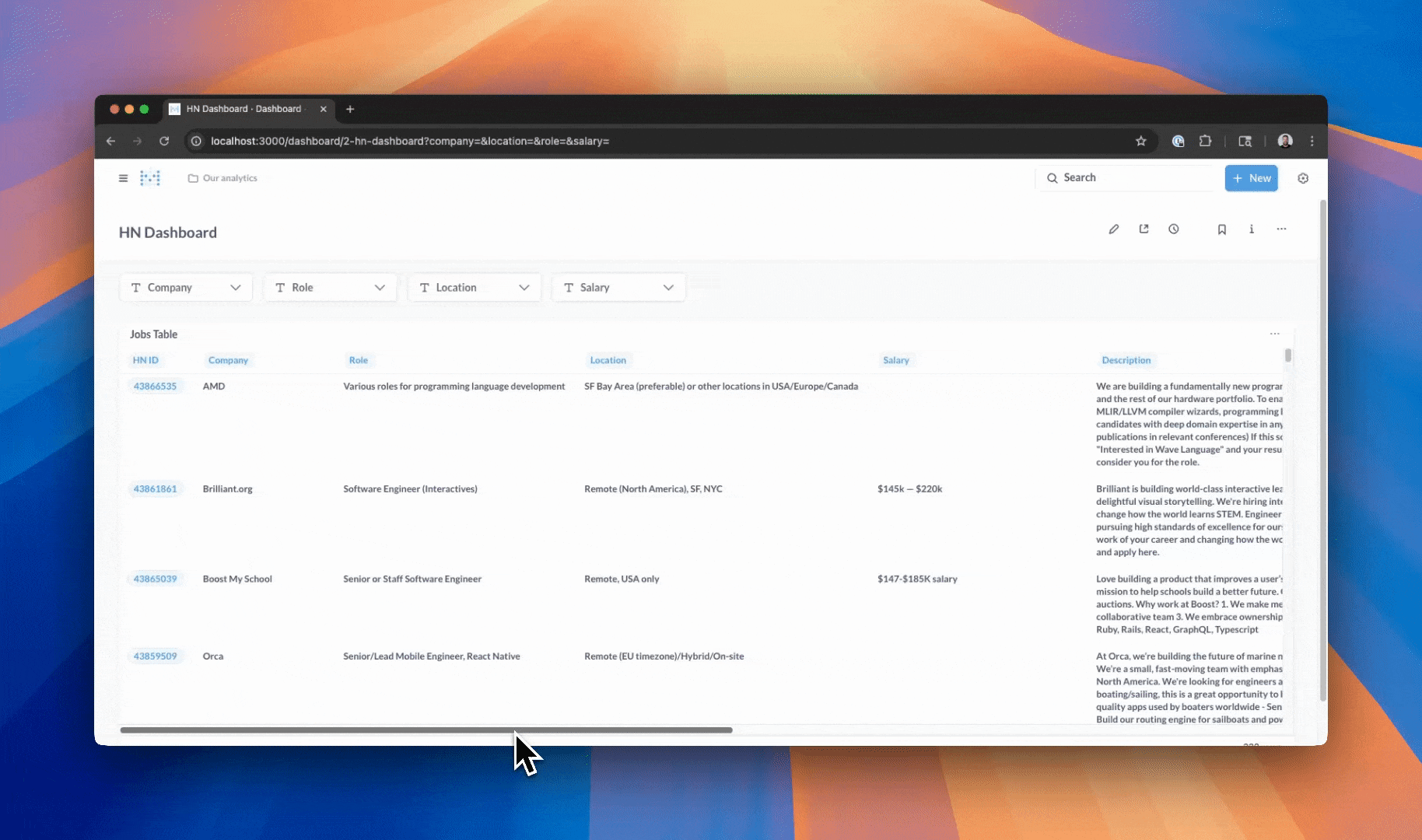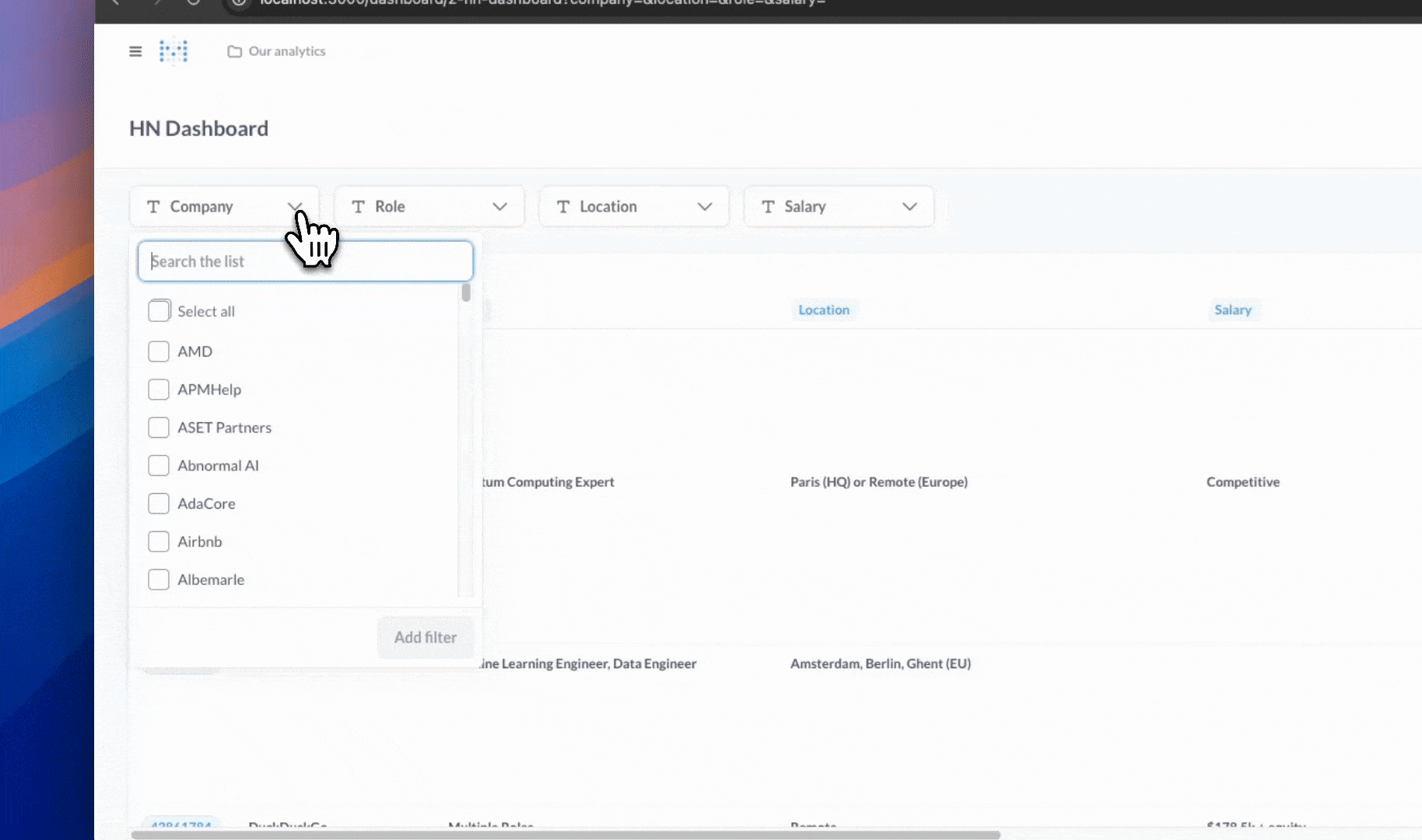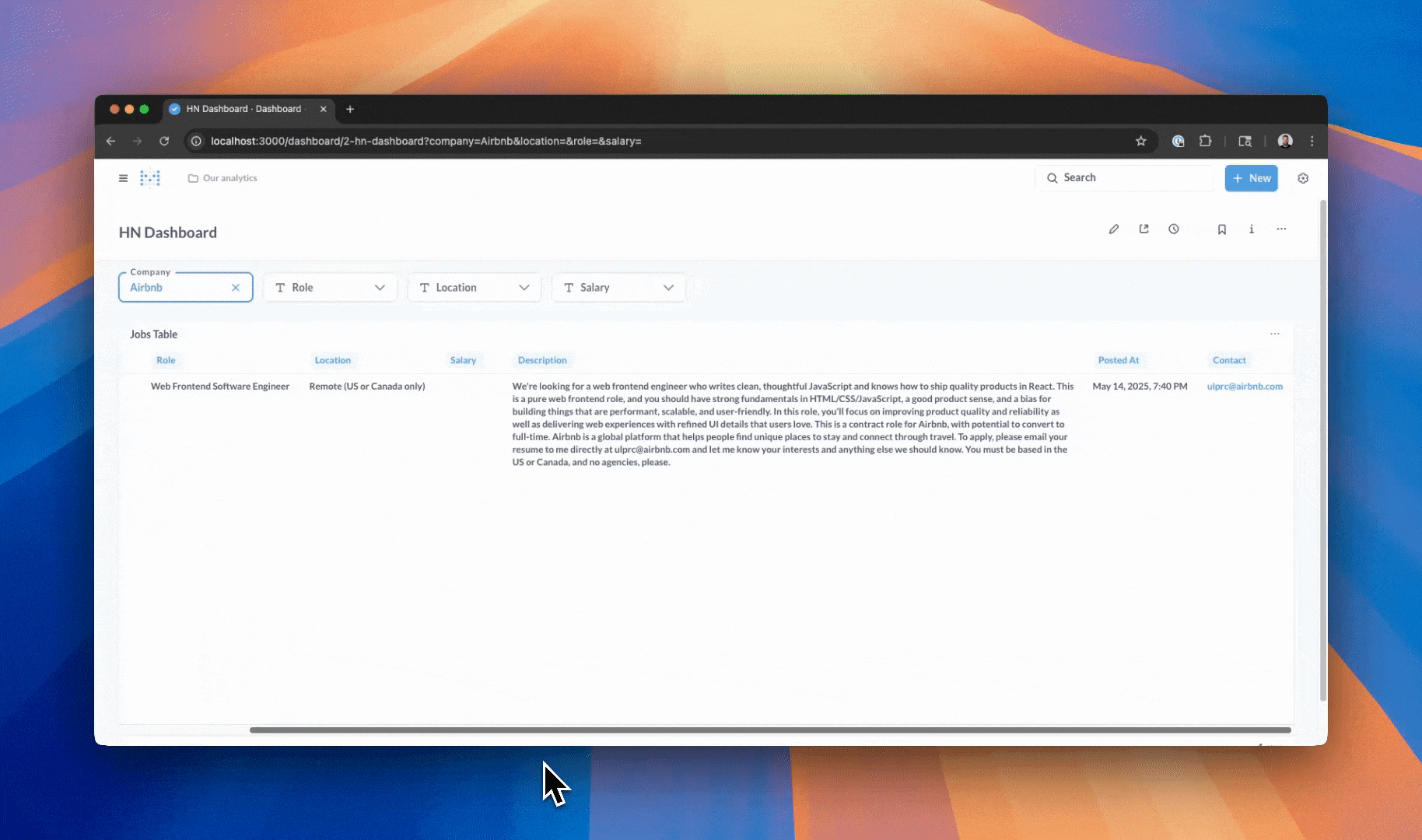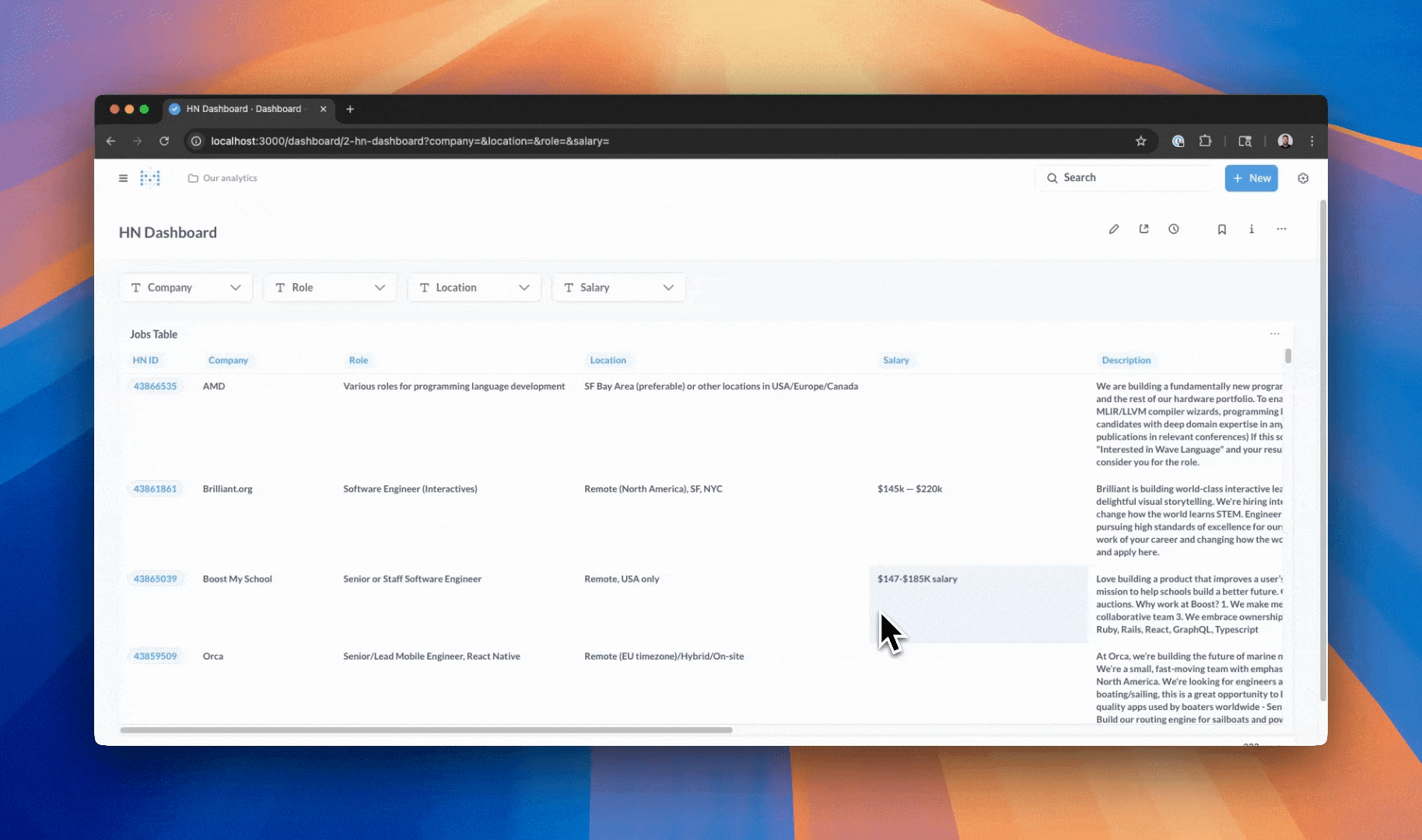
Metabase connects directly to the Postgres database and gives you a clean UI to explore the data.
I made a little table that lets you:
- Filter by company, role, location, and salary
- Link to thread ID
Potential enhancements
Here are a few ideas to take this project to the next level:
- Automate monthly updates: Use GitHub Actions to fetch and parse new “Ask HN: Who is hiring?” threads automatically each month.
- Deploy a public dashboard: Share a live Metabase dashboard for anyone to explore job listings without needing to run the code.
- Add notification alerts: Set up email or Slack notifications for new job postings that match specific criteria, like role or location.
Take it for a spin and contribute
Check out the full code and detailed setup instructions on GitHub. Whether you’re searching for your next role or simply curious, feel free to clone the repo and try it out. Better yet, consider contributing. If you have a feature idea, a bug fix, or any improvements, submit a pull request or open an issue.
Thanks for reading, and good luck with your job search!